共分散構造分析(SEM)モデル構築について
卒業論文・修士論文・博士論文・投稿論文で、潜在変数を含む仮説モデルを検証し、パス図・適合度指標・標準化係数まで説得的に示したい方へ
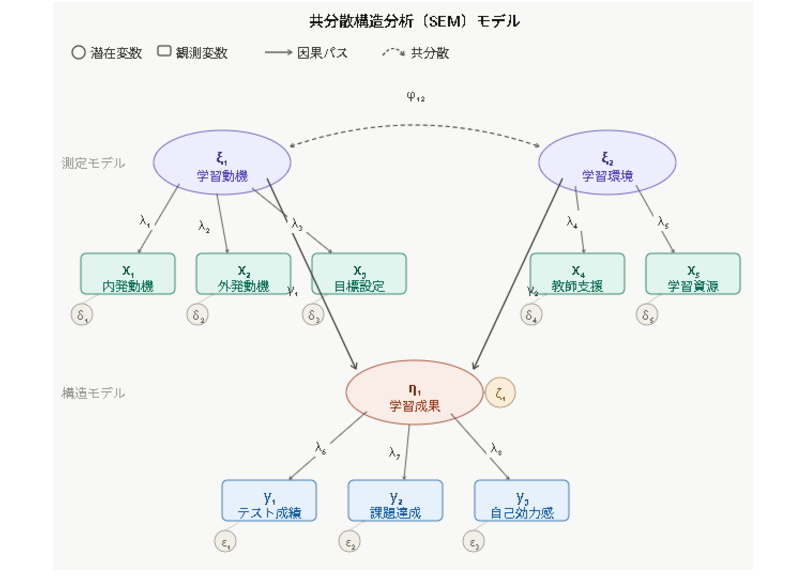
共分散構造分析(SEM:Structural Equation Modeling)は、心理学、教育学、看護学、医療研究、社会福祉学、経営学、マーケティング、観光研究、組織研究などで広く用いられる多変量解析の一つです。 SEMは、観測された質問項目や尺度得点だけでなく、その背後にある 潜在変数 を設定し、変数同士の関係を同時に検討できる点に特徴があります。
たとえば、「心理的所有感が高いほど幸福感が高まる」「学習意欲が授業満足度を媒介して継続意向に影響する」「職場風土が心理的安全性を通じて離職意向を下げる」といった研究では、単純な相関分析や重回帰分析だけでなく、複数の関係を一つの仮説モデルとして検証できるSEMが有効です。
ただし、SEMでは分析ソフトにデータを入れるだけでは十分ではありません。 研究仮説に基づく モデル構築、 潜在変数と観測変数の対応関係を示す 測定モデル、 潜在変数同士の因果的仮説を示す 構造モデル、 さらに、モデル全体がデータにどの程度適合しているかを示す 適合度指標 を総合的に検討する必要があります。
本記事では、 共分散構造分析、 SEM、 SEM モデル構築、 潜在変数、 観測変数、 パス図、 確認的因子分析、 適合度指標、 AMOS、 lavaan、 Mplus などを調べている方に向けて、SEMモデル構築の基本、分析の流れ、論文での書き方、注意点を具体的に整理します。
まず押さえたいのは、 SEMのモデル構築は、統計ソフト上でパスを引く作業ではなく、理論・先行研究・尺度構成・研究仮説をもとに、どの変数がどの変数へ影響するのかを検証可能な形に整理する作業 だということです。モデルの見た目よりも、なぜそのパスを設定したのかを説明できることが重要です。
共分散構造分析(SEM)とは何か
共分散構造分析(SEM)とは、複数の変数間の関係を同時に分析するための統計手法です。 SEMでは、観測変数同士の関係だけでなく、観測変数の背後にある潜在変数を設定し、その潜在変数同士の関係をモデル化できます。 そのため、心理尺度、態度尺度、満足度尺度、意識調査、行動意図、組織要因などを扱う研究に適しています。
SEMの大きな特徴は、測定モデルと構造モデルを同時に扱える点です。 測定モデルでは、潜在変数がどの観測変数によって測定されるのかを示します。 構造モデルでは、潜在変数同士、または潜在変数と観測変数の間にどのような影響関係があるのかを示します。
SEMでできること
SEMでは、複数の回帰関係を一つのモデルとして同時に推定できます。 たとえば、独立変数、媒介変数、従属変数を含むモデルを作成し、直接効果と間接効果を同時に検討できます。 また、複数の質問項目から構成される尺度を潜在変数として扱うことで、測定誤差を考慮した分析が可能になります。
さらに、複数の群でモデルが同じように成立するかを確認する多母集団同時分析、尺度の測定不変性の検討、媒介分析、階層的な仮説モデルの検証などにも応用できます。 卒論や修論ではシンプルなパスモデルから始めることが多く、博士論文や投稿論文ではより理論的に精緻なモデルが求められることがあります。
回帰分析や因子分析との違い
回帰分析は、ある従属変数に対して、複数の独立変数がどの程度影響するかを検討する方法です。 因子分析は、複数の観測変数の背後にある共通因子を探索または確認する方法です。 SEMは、これらの考え方を拡張し、因子構造と変数間の影響関係を一つのモデルとして扱える点に特徴があります。
たとえば、因子分析で「心理的所有感」「幸福感」「関係満足」という潜在変数を確認し、その後、SEMで「心理的所有感が関係満足を通じて幸福感に影響する」というモデルを検証することができます。 このように、SEMは測定と構造の両方を同時に考える分析方法です。
SEMにおけるモデル構築とは何か
SEMにおけるモデル構築とは、研究仮説をパス図として表現し、統計的に検証可能な形に整理する作業です。 どの変数を潜在変数として扱うのか、どの観測変数で測定するのか、どの変数からどの変数へパスを設定するのか、誤差項や共分散をどのように扱うのかを決める必要があります。
モデル構築では、先行研究や理論的枠組みとの整合性が重要です。 SEMでは、ソフト上で多数のパスを自由に設定できますが、根拠のないパスを増やすと、統計的には適合度が改善しても、研究としての説明力が弱くなることがあります。 そのため、モデルは「適合度がよいか」だけでなく、「理論的に説明できるか」という観点から構築する必要があります。
特に卒論・修論・博士論文・投稿論文では、モデル図を示すだけでなく、 なぜその潜在変数を設定したのか、なぜそのパスを仮定したのか、なぜそのモデルで研究目的に答えられるのか を文章で説明することが求められます。
潜在変数と観測変数の設定
SEMモデル構築で最初に重要になるのが、潜在変数と観測変数の設定です。 潜在変数とは、直接観測することはできないものの、複数の質問項目や指標を通じて測定される概念です。 たとえば、幸福感、学習意欲、自己効力感、心理的安全性、職務満足、ブランド愛着などが潜在変数として扱われます。
観測変数とは、実際にアンケートや測定によって得られる変数です。 たとえば、「私は現在の生活に満足している」「この授業は理解しやすい」「職場では安心して意見を言える」といった質問項目が観測変数になります。 SEMでは、これらの観測変数がどの潜在変数を測定しているのかを明確に設定します。
測定モデルの考え方
測定モデルとは、潜在変数と観測変数の関係を示すモデルです。 たとえば、「心理的安全性」という潜在変数を3つまたは4つの質問項目で測定する場合、それぞれの項目から心理的安全性を測定していることをパス図で示します。
測定モデルの妥当性を確認するためには、確認的因子分析(CFA)を行うことが一般的です。 各観測変数が想定した潜在変数に十分に関連しているか、因子負荷量が適切か、モデル全体の適合度が許容できるかを確認します。
構造モデルの考え方
構造モデルとは、潜在変数同士、または潜在変数と観測変数の間の関係を示すモデルです。 たとえば、「心理的所有感」が「関係満足」に影響し、「関係満足」が「幸福感」に影響するという仮説がある場合、これらの潜在変数間に方向性のあるパスを設定します。
構造モデルでは、直接効果だけでなく、媒介効果や間接効果を検討することもあります。 研究仮説が複雑になるほど、パスの設定根拠を明確に示すことが重要になります。
SEMモデル構築の基本手順
SEMモデル構築は、単に統計ソフトで図を描くことではなく、研究目的、理論、尺度、データ、分析手順を一貫させる作業です。 一般的には、次のような流れで進めます。
| 段階 | 主な作業内容 |
|---|---|
| 1. 研究仮説の整理 | 先行研究や理論に基づき、変数間の関係を明確にする |
| 2. 潜在変数の設定 | 研究で扱う概念を整理し、尺度項目との対応を確認する |
| 3. 測定モデルの確認 | 確認的因子分析により、潜在変数と観測変数の対応を検討する |
| 4. 構造モデルの設定 | 仮説に基づき、潜在変数間または観測変数間のパスを設定する |
| 5. 適合度指標の確認 | CFI、TLI、RMSEA、SRMR、χ²値などを確認する |
| 6. パス係数の解釈 | 標準化係数、有意性、直接効果、間接効果を確認する |
| 7. 論文への記載 | Methods、Results、Discussionに分析手順と結果を整理する |
この流れを踏むことで、SEMの分析結果を単なる図や数値ではなく、研究目的に対応した検証結果として説明できます。 特に、モデル構築の段階で仮説が曖昧だと、分析後に結果の解釈が難しくなります。
確認的因子分析(CFA)との関係
SEMモデル構築では、確認的因子分析(CFA)が重要な役割を果たします。 CFAは、あらかじめ想定した因子構造がデータに適合しているかを確認する分析です。 探索的因子分析が「どのような因子がありそうか」を探索するのに対し、CFAは「想定した因子構造が妥当か」を検証する方法です。
SEMで潜在変数を使う場合、各潜在変数が適切な観測変数によって測定されているかを確認する必要があります。 測定モデルが不安定なまま構造モデルを検討すると、潜在変数間の関係の解釈も不安定になります。 そのため、CFAによって因子負荷量、適合度、潜在変数間の相関を確認したうえで、構造モデルへ進むことが望ましいです。
論文では、「まず測定モデルの妥当性を確認し、その後に構造モデルを検討した」と書くことで、分析手順の透明性が高まります。 また、尺度の信頼性や妥当性を示すために、Cronbachのα係数、合成信頼性、平均分散抽出などを併せて検討する場合もあります。
適合度指標の読み方
SEMでは、モデル全体がデータにどの程度適合しているかを確認するために、複数の適合度指標を用います。 代表的な指標には、χ²値、CFI、TLI、RMSEA、SRMRなどがあります。 どれか一つの指標だけで判断するのではなく、複数の指標を総合的に確認することが重要です。
| 適合度指標 | 確認する内容 |
|---|---|
| χ²値 | モデルとデータの乖離を検討する。ただしサンプルサイズの影響を受けやすい |
| CFI | 比較適合度指標。一般に高い値ほどモデルの適合がよいと解釈される |
| TLI | モデルの複雑さを考慮した比較指標として用いられる |
| RMSEA | 近似誤差を評価する指標。一般に低い値ほど適合がよいと解釈される |
| SRMR | 観測された相関とモデルが再現した相関の残差を示す指標 |
適合度指標は、モデルが完全に正しいことを証明するものではありません。 適合度がよくても理論的に不自然なモデルであれば、研究としての説得力は弱くなります。 反対に、適合度がやや弱い場合でも、研究目的やサンプル特性、モデルの理論的意味を踏まえて慎重に解釈する必要があります。
パス係数・標準化係数・間接効果の解釈
SEMの結果では、各パスの係数を確認します。 パス係数は、ある変数が別の変数にどの程度影響しているかを示す値です。 標準化係数を用いると、変数の単位をそろえたうえで影響の大きさを比較しやすくなります。
たとえば、「心理的所有感から幸福感への標準化パス係数が.42であった」と記載する場合、心理的所有感が高いほど幸福感も高い傾向にあることを示します。 ただし、横断データの場合には、統計モデル上の方向性と実際の因果関係を区別して解釈する必要があります。
SEMでは、直接効果だけでなく間接効果も重要です。 たとえば、AがBを通じてCに影響する場合、AからCへの直接パスが有意でなくても、AからB、BからCの経路を通じた間接効果が意味を持つ場合があります。 媒介分析を行う際には、ブートストラップ法などを用いて間接効果の信頼区間を確認することがあります。
モデル修正で注意すべきこと
SEMでは、修正指数を参考にしてモデルを修正することがあります。 たとえば、誤差項間の共分散を追加したり、パスを追加したりすることで、適合度が改善する場合があります。 しかし、修正指数だけを根拠にモデルを変更することは避けるべきです。
モデル修正は、理論的・実質的に説明できる場合に限って行う必要があります。 たとえば、同じ尺度内の似た表現の質問項目に誤差共分散を設定する場合には、項目内容の類似性という根拠を示す必要があります。 根拠のない修正を繰り返すと、分析対象データに過度に適合したモデルになり、別のデータでは再現されにくくなる可能性があります。
論文では、 最初に設定した理論モデル、修正を行った理由、最終モデルに至った根拠 を明確に示すことが重要です。 特に投稿論文では、探索的なモデル修正と検証的なモデル検証を混同しないよう注意が必要です。
論文でのMethods・Resultsの書き方
SEMを論文で用いる場合、Methodsではモデルの構築根拠、分析対象、使用尺度、推定方法、使用ソフト、欠測値処理、適合度指標を明確に記述します。 Resultsでは、測定モデル、構造モデル、適合度指標、パス係数、間接効果などを整理して示します。
- 先行研究に基づき、潜在変数間の関係を仮定したSEMモデルを構築した。
- 各潜在変数は、対応する複数の観測変数によって測定した。
- まず確認的因子分析により測定モデルの適合度を確認した。
- 次に、構造モデルを推定し、潜在変数間の標準化パス係数を確認した。
- モデル適合度は、χ²値、CFI、TLI、RMSEA、SRMRを用いて評価した。
- 媒介効果については、間接効果と信頼区間を確認した。
Resultsの記載では、「有意だった」「有意ではなかった」だけで終わらせないことが重要です。 どのパスが仮説を支持したのか、どのパスが支持されなかったのか、モデル全体の適合度はどうだったのかを、表や図とともに説明します。
SEMモデル構築でよくある失敗
SEMモデル構築でよくある失敗は、理論的根拠が弱いまま複雑なモデルを作ってしまうことです。 SEMは多くのパスを同時に推定できるため、さまざまな関係を盛り込みたくなります。 しかし、パスが多すぎるモデルは、解釈が難しくなり、研究仮説との対応も不明確になります。
- 先行研究の根拠がないパスを多数設定している
- 潜在変数と観測変数の対応関係が曖昧である
- 確認的因子分析を行わずに構造モデルへ進んでいる
- 適合度指標だけを見てモデルの妥当性を判断している
- 修正指数に従って根拠のないパスや誤差共分散を追加している
- サンプルサイズに対してモデルが複雑すぎる
- 横断データであるにもかかわらず、強い因果表現を用いている
- パス図は示しているが、MethodsやResultsで説明が不足している
SEMでは、統計的に推定できることと、研究として説明できることを区別する必要があります。 良いSEMモデルとは、適合度が高いモデルというだけでなく、研究目的、理論、尺度、データ、解釈が一貫しているモデルです。
スタットエージェントで対応できるSEM分析支援
スタットエージェントでは、卒業論文、修士論文、博士論文、投稿論文、医学論文、看護研究、心理学研究、教育学研究、経営学研究、社会調査、企業調査に向けて、 共分散構造分析(SEM)、確認的因子分析(CFA)、パス解析、媒介分析、多母集団同時分析、尺度分析、適合度指標の整理、パス図作成、結果の解釈、論文・報告書への記載支援を行っております。
特に、SEMモデル構築の支援では、 研究仮説の整理、潜在変数と観測変数の対応確認、測定モデルの構築、構造モデルの設定、適合度指標の確認、標準化係数の解釈、図表作成、Methods・Results・Discussionの文章化 まで一貫して整理できます。
「SEMのモデル図をどう作ればよいかわからない」 「AMOSやlavaanで分析した結果を論文にどう書けばよいかわからない」 「適合度指標の解釈が不安」 「媒介分析や多母集団同時分析まで検討したい」 「卒論・修論・投稿論文で使えるSEMモデルに整えたい」 といった場合でも、研究目的とデータ内容に応じて具体的にご相談いただけます。
よくある質問
Q1. 共分散構造分析(SEM)はどのような研究に向いていますか?
SEMは、複数の変数間の関係を同時に検討したい研究や、潜在変数を含む仮説モデルを検証したい研究に向いています。 心理尺度、態度尺度、満足度、行動意図、組織要因、教育効果、看護研究、マーケティング調査などで用いられます。
Q2. SEMでは必ず潜在変数を使う必要がありますか?
必ずしも潜在変数を使う必要はありません。 観測変数だけで構成されるパス解析もSEMの枠組みで扱われることがあります。 ただし、尺度項目から構成される概念を扱う場合には、潜在変数を設定することで測定誤差を考慮した分析が可能になります。
Q3. SEMモデルの適合度が悪い場合はどうすればよいですか?
まず、測定モデル、データの特徴、尺度項目、欠測値、外れ値、サンプルサイズ、モデルの理論的妥当性を確認する必要があります。 修正指数を参考にすることはありますが、理論的根拠のない修正を繰り返すことは避けるべきです。
Q4. SEMではどの適合度指標を見ればよいですか?
一般的には、χ²値、CFI、TLI、RMSEA、SRMRなどを組み合わせて確認します。 どれか一つの指標だけで判断するのではなく、モデルの理論的妥当性、サンプルサイズ、研究分野の慣例を踏まえて総合的に判断することが重要です。
Q5. 卒論や修論でもSEMは使えますか?
使えます。 ただし、モデルが複雑になりすぎないようにし、研究仮説、尺度、サンプルサイズ、分析手順を明確にする必要があります。 初めてSEMを用いる場合は、シンプルな測定モデルと構造モデルから設計することが望ましいです。
まとめ|SEMモデル構築は、理論・尺度・データ・解釈を一貫させる作業である
共分散構造分析(SEM)は、潜在変数を含む複雑な仮説モデルを検証できる有効な分析手法です。 ただし、SEMの価値は、単にパス図を作成することや、適合度指標を並べることにあるのではありません。 重要なのは、研究目的に基づき、潜在変数と観測変数を適切に設定し、測定モデルと構造モデルを理論的に構築することです。
SEMモデル構築では、 先行研究に基づく仮説設定、尺度構成の確認、確認的因子分析、適合度指標の評価、標準化パス係数の解釈、媒介効果の検討、論文での記述 までを一貫して考える必要があります。 適合度だけでなく、理論的に説明できるモデルであるかどうかを常に確認することが重要です。
スタットエージェントでは、共分散構造分析(SEM)、確認的因子分析(CFA)、パス解析、媒介分析、多母集団同時分析、尺度分析、パス図作成、統計解析、論文・報告書への記載支援まで対応しております。 SEMのモデル構築に不安がある、 パス図や適合度指標を正しく整理したい、 卒論・修論・投稿論文で使えるSEM分析に整えたい といった場合には、お気軽にご相談ください。
